Reading the blogs of lcamtuf and Chris Evans is really what got me interested in browser security,
so I’m always on the lookout for novel cross-domain data theft vectors. Today I’m going to go into
the discovery and exploitation of such a bug: A timing attack on Firefox’s document.elementFromPoint and document.caretPositionFromPoint implementations.
Initial Discovery
I was looking at ways to automatically exploit another bug that required user interaction when I noticed elementFromPoint and caretPositionFromPoint on the MDN. Curious as to how they behaved with frames, I did a little testing.
I made an example page to test:
1 2 3 | |
elementFromPoint(x,y) behaved exactly as I expected, when used in the web console it returned the iframe on my page:
1 2 | |
caretPositionFromPoint(x,y), however, was returning elements from the page on cbc.ca!
1 2 | |
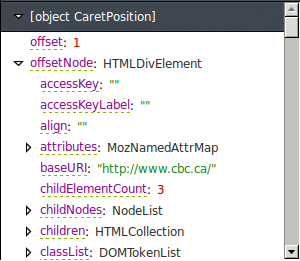
But there was a small snag: I couldn’t actually access the CaretPosition’s offsetNode from JS without getting a security exception.
It seems that Firefox noticed that offsetNode was being set to an element from a cross-origin document, and wrapped the CaretPosition object
so that I couldn’t access any of its members from my document. Great.
However, I found I could access offsetNode when it was set to null. offsetNode seems to be set to null when the topmost
element at a given point is a button, and that includes scrollbar thumbs. That’s great for us, because knowing the size and location of the frame’s scrollbar thumb
tells us how large the framed document is, and also allows us to leak which elements exist on the page.
For example here’s what we can infer about https://tomcat.apache.org/tomcat-5.5-doc/ssl-howto.html#Create_a_local_Certificate_Signing_Request_(CSR) through its scrollbars:
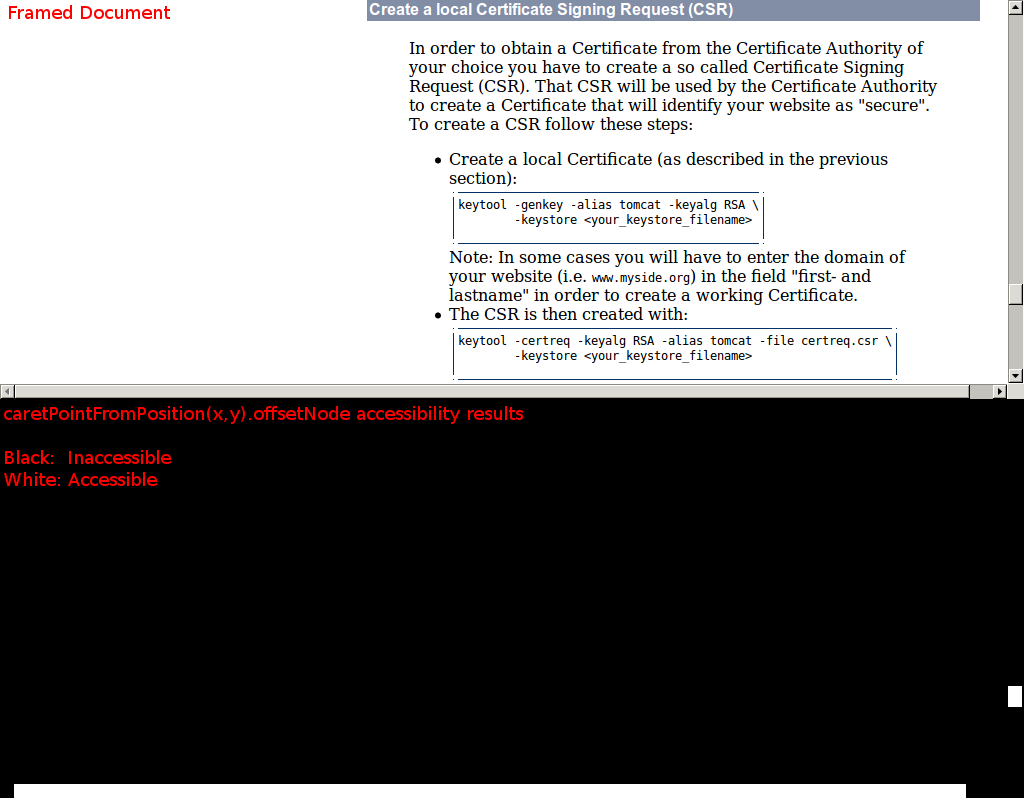
The vertical scrollbar thumb has obviously moved, so we know that an element with an id of Create_a_local_Certificate_Signing_Request_(CSR) exists in the framed document.
The following function is used to test offsetNode accessibility at a given point in the document:
1 2 3 4 5 6 7 8 | |
Digging Deeper
Knowing the page’s size and whether certain elements are present is nice, but I wanted more. I remembered Paul Stone’s excellent paper about timing attacks on browser renderers and figured a timing attack might help us here.
caretPositionFromPoint has to do hit testing on the document to determine what the topmost element is at a given point,
and I figured that’s not likely to be a constant time operation. It was also clear that hit testing was being performed on cross-origin frame contents, since caretPositionFromPoint was returning elements from them.
I guessed that the time it took for a caretPositionFromPoint(x,y) call to return would leak information about the element at (x,y).
To test my theory I made a script that runs caretPositionFromPoint(x,y) on a given point 50 times, then stores the median time that the call took to complete. Using the median is important so we can eliminate timing differences due to unrelated factors, like CPU load at the time of the call.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Once we’ve gathered timing measurements for all of the points across the iframe, we can make a visualization of the differences:
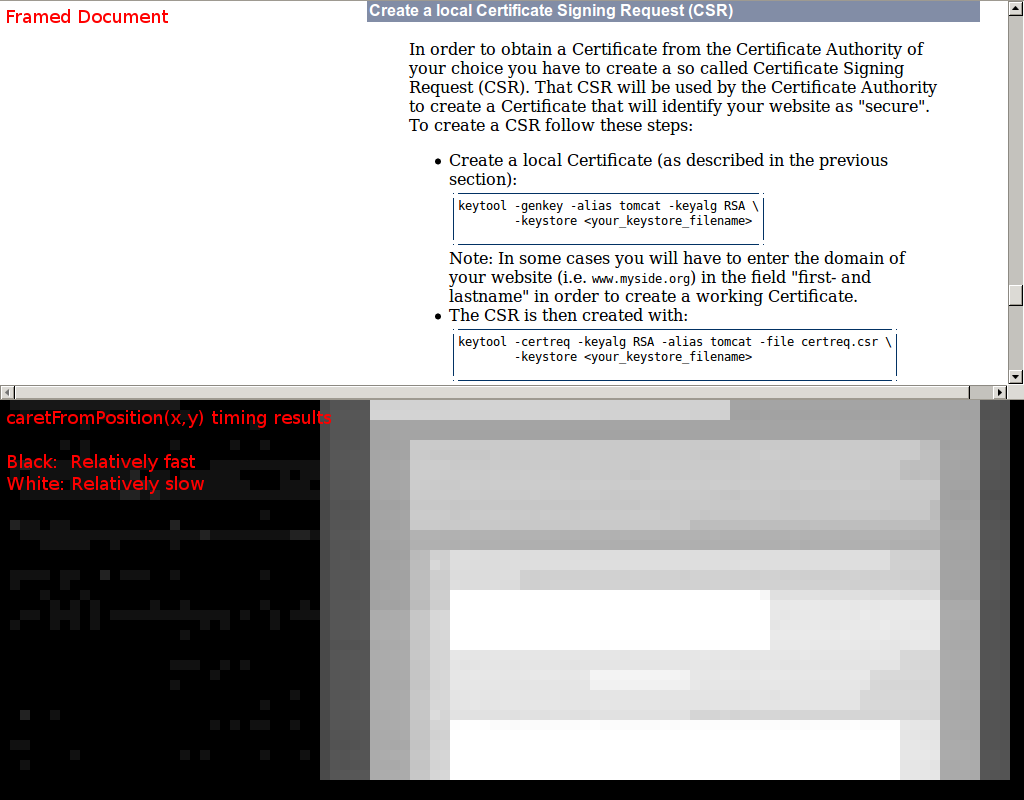
Neat.
You can see a number of things in the timing data: the bounding boxes of individual elements, how the lines of text wrap, the position of the bullets in the list, etc.
It also seems that even though elementFromPoint doesn’t return elements from the framed document, it still descends into it for its hit testing, so it’s vulnerable to
the same timing attack as caretPositionFromPoint.
Stealing Text
So we can infer quite a bit about the framed document from the timing information, but can we actually steal text from it? Maybe, with a lot of work, depending on the page’s styling.
I’d hoped that caretPositionFromPoint’s real purpose (determining what character index the caret should be at for a given point) would yield large enough timing differences to leak the width of individual characters, but that didn’t seem to be the case.
Since we can tell how wide a line of text is, we can extract text using a similar method to sirdarckcat’s. First we measure how long the line is, then we make the iframe more narrow to force the text to wrap, then we subtract the new width of the the line from the old width, giving us the width of the word that just wrapped.
Since most sites use variable-width fonts (“O” and “i” are different widths on this blog, for example,) many small words have distinct widths that make them easy to pick out. With longer words, there may be a number of valid words with that width, however an attacker may be able to determine what word fits best using the context of the surrounding words.
Note that since we need to force text wrapping to get these measurements, it’s harder to steal text from fixed-width pages, or pages that display a horizontal scrollbar instead of wrapping text (like view-source: URIs.) Pages that use fixed-width fonts are also more difficult to analyze because characters do not have distinct widths, we can only determine the number of characters in a word.
Working Examples
Note that the last Firefox version these actually work in is 26, if you want to try them out you’ll have to find a download for it.
The Fix
Judging from Robert O’Callahan’s fix, it looks like Firefox was using a general hit testing function that descended cross-document for both elementFromPoint and caretPositionFromPoint. The fix was to disable cross-document descent in the hit testing function when called by either elementFromPoint or caretPositionFromPoint.
Disclosure Timeline
- Dec. 11 2013: Discovered
caretPositionFromPointleaked info throughoffsetNodeaccessibility - Dec. 13 2013: Notified Mozilla
- Dec. 13 2013: Mozilla responds
- Dec. 15 2013: Discovered timing info leaks in both
elementFromPointandcaretPositionFromPoint - Dec. 16 2013: Sent update to Mozilla
- Dec. 16 2013: Mozilla responds
- Dec. 18 2013: Fix committed
- Jan. 16 2014: Fix pushed to Beta channel
- Feb. 04 2014: Fix pushed to Stable channel and advisory posted